Code alignment options in llvm.
25 Jan 2018
Contents:
Subscribe to my newsletter, support me on Patreon or by PayPal donation.
In my previous post I discussed code alignment issues that could arise when you benchmarking your code. Simon in the comments mentioned code alignment option ‘-align-all-nofallthru-blocks’. If we look at what description says about this option it’s not clear what this option is doing. So, I decided to give some clear examples of what it’s doing.
In latest llvm (as of 25.01.2018) there are 3 machine-independent option for controling code alignment:
-align-all-blocks=<uint>
Force the alignment of all blocks in the function.
-align-all-functions=<uint>
Force the alignment of all functions.
-align-all-nofallthru-blocks=<uint>
Force the alignment of all blocks that have no fall-through
predecessors (i.e. don't add nops that are executed).
Let’s take an example like this:
int foo();
int bar();
void func(int* a)
{
for (int i = 0; i < 32; ++i)
a[i] += 1;
if (a[0] == 1)
a[0] += foo();
else
a[0] += bar();
}
For this code compiled with -O2 -march=skylake -fno-unroll-loops clang will produce this assembly:
0000000000000040 <_Z4funcPi>:
40: push rbx
41: mov rbx,rdi
44: mov rax,0xffffffffffffff80
4b: vpcmpeqd ymm0,ymm0,ymm0
4f: nop
50: vmovdqu ymm1,YMMWORD PTR [rbx+rax*1+0x80]
59: vpsubd ymm1,ymm1,ymm0
5d: vmovdqu YMMWORD PTR [rbx+rax*1+0x80],ymm1
66: add rax,0x20
6a: jne 50 <_Z4funcPi+0x10>
6c: cmp DWORD PTR [rbx],0x1
6f: jne 7b <_Z4funcPi+0x3b>
71: vzeroupper
74: call 79 <_Z4funcPi+0x39>
79: jmp 83 <_Z4funcPi+0x43>
7b: vzeroupper
7e: call 83 <_Z4funcPi+0x43>
83: add DWORD PTR [rbx],eax
85: pop rbx
86: ret
Note that the loop is already aligned on a 16B boundary.
And here is the vizualization (created with this tool) for this assembly where we can see the basic blocks (BB):
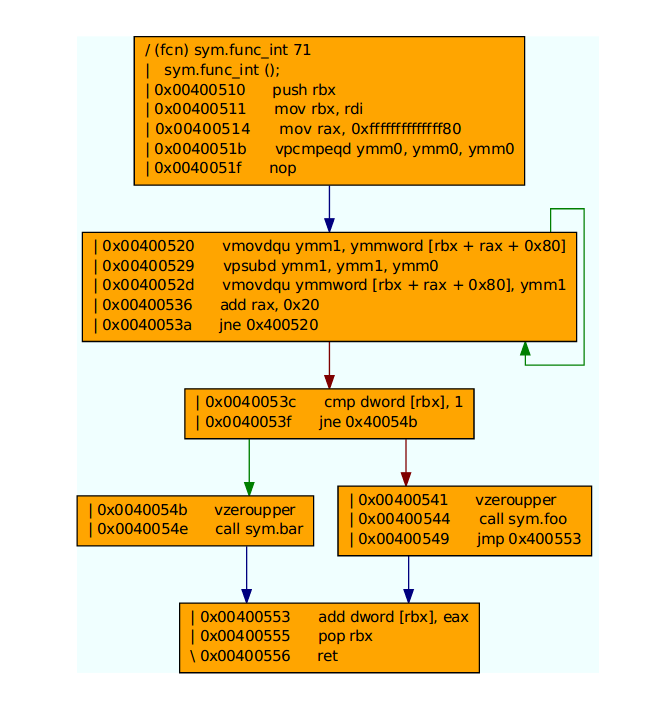
Below I will show the difference in different code aligning options. All the code and scripts that I used can be found here.
align-all-functions
This option will align all your functions on a bounday specified in the parameter. For example, -mllvm -align-all-functions=5 will align all functions on a 32B boundary (2^5=32).
Regarding our case (don’t look at the offsets in visual representation) function is already aligned at 64B boundary so, the only difference will be if we specify -mllvm -align-all-functions=7:

align-all-blocks
Apply this option carefully because it can cause lot of nops be added into the assembly. Adding -mllvm -align-all-blocks=5 yields this diff:
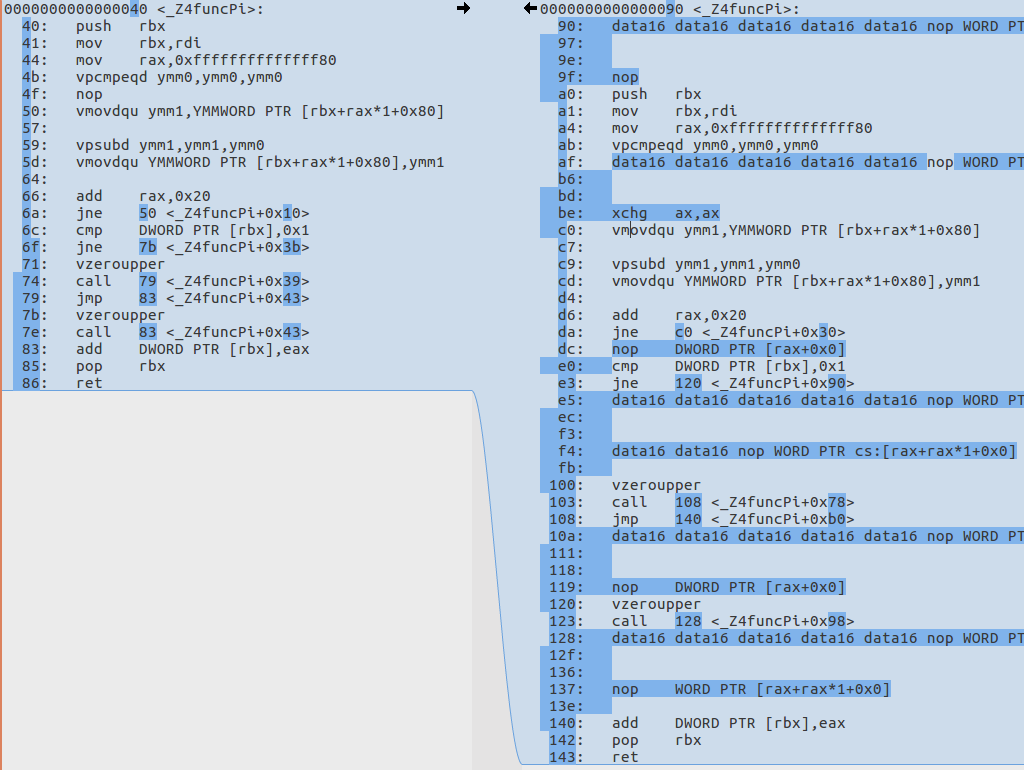
Note that this option does not align the function beginning, but rather it’s first basic block.
I will not show the results of what will happen if I will specify 6 or 7, because it won’t fit on a screen.
align-all-nofallthru-blocks
This option as opposed to blindly aligning all blocks does it in a smarter way. The description looks complicated, but in fact it’s really simple. Algorithm looks like this: for each BB we check if a previous BB can reach current BB by falling through. If it can, we don’t align such current, because it means that we will insert NOPs into the executed path (as the opposite to -align-all-blocks). If the previous BB can’t reach current BB by falling through, it means that the only way we can reach current BB is by jumping into it and the previous block ends with unconditional branch, so we can safely insert nops between previous and current BB, knowing that those NOPs won’t be executed.
In our function there is only one such BB (that has a call to bar()). Here is the diff for -mllvm -align-all-nofallthru-blocks=5:
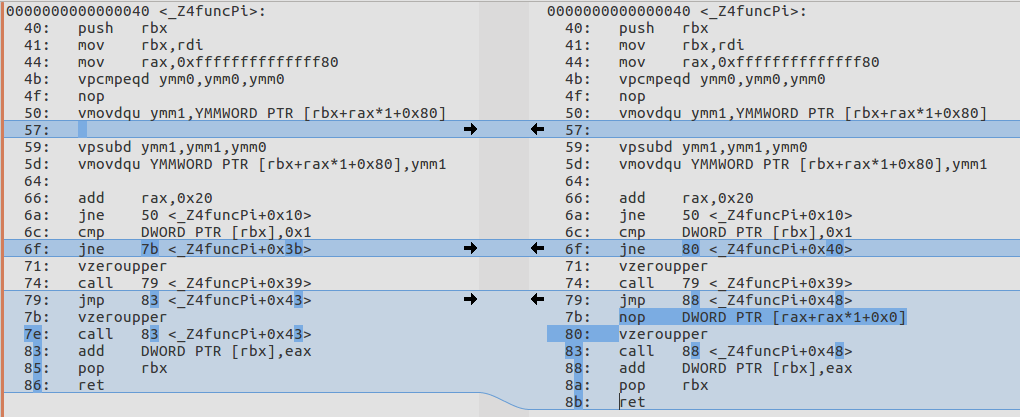
Again, all the code and scripts that I used can be found here, so free to play with different options.
Conclusion
By now I hope it’s clear what those code alignment options mean, but I encourage you to use them with care. The most safe IMHO is the -align-all-nofallthru-blocks, however it also doesn’t come for free - it increases the binary size.
All content on Easyperf blog is licensed under a Creative Commons Attribution 4.0 International License